22 Sampling Distribution of Sample Means
22.1 Repeated Sampling For Means
Suppose we start with a population distribution that has a certain population mean \(\mu\) and standard deviation \(\sigma\).
There is nothing special about this distribution. For example, it does not have to be normal. It could be. But what we are going to do works for any distribution actually.
We will call this the original distribution, and sometimes we refer to it as the \(x\)-distribution.
Then imagine we take samples of a certain size \(n\) over and over again, each time we calculate the sample mean \(\bar x\) from our sample.
So we:
- choose a sample and calculate a sample mean \(\bar x\)
- choose a sample and calculate another sample mean \(\bar x\)
- choose a sample and calculate another sample mean \(\bar x\)
- and so on
Usually the sample means are close to the population mean but sometimes they are farther away (though this is less likely the farther away we get from the population mean).
It turns out…
If we then plot all these sample means on a histogram, we get something that looks like a normal curve!
This is true if the sample size is big enough even if we start with the original distribution not being normal.
22.2 Start With An Original Distribution (\(x\)-distribution)
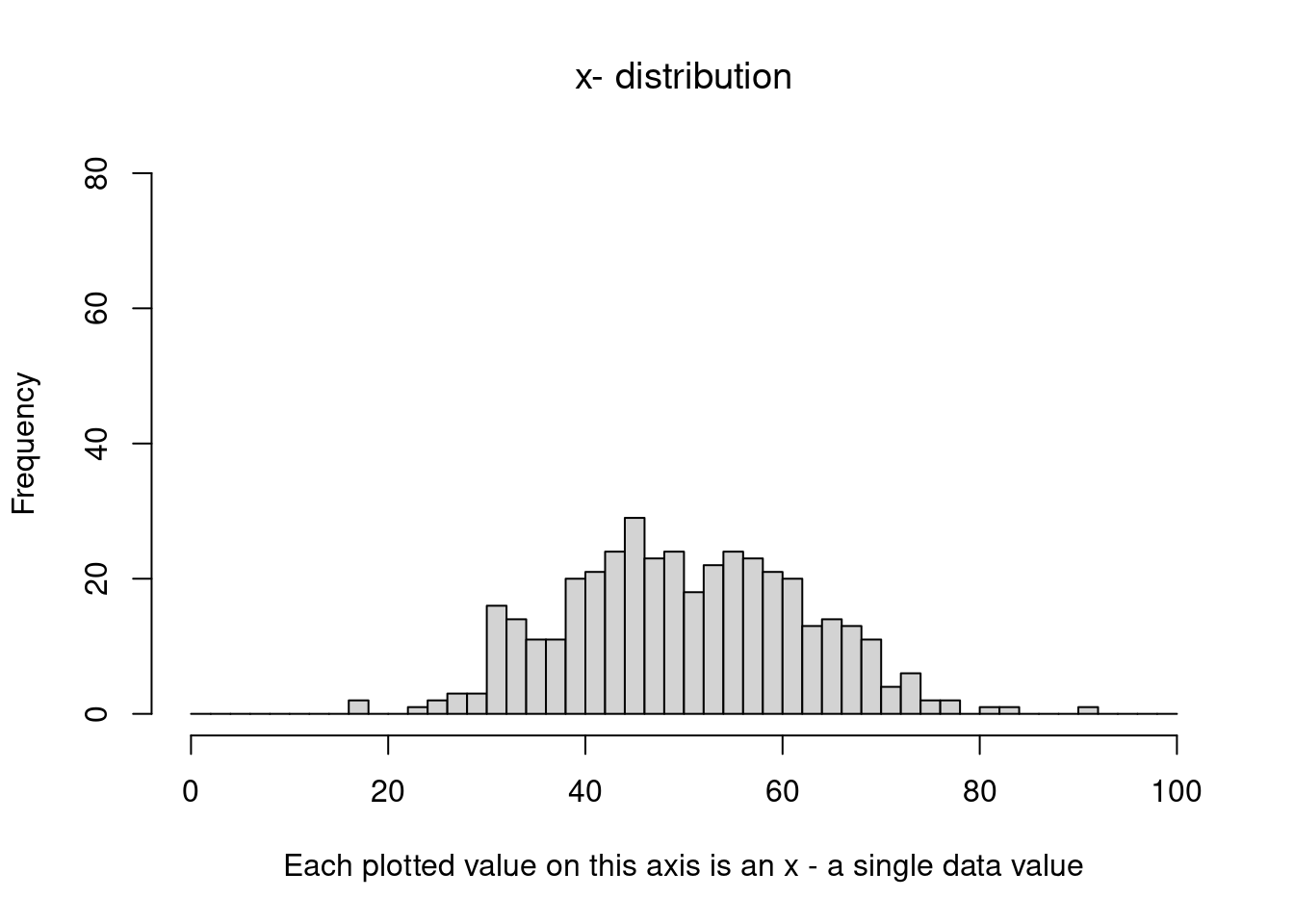
Here we start with an original distribution which is normal (call it the \(x\)-distribution). It has mean \(\mu=50\) and standard deviation of \(\sigma = 12\).
Lets pick some samples from this distribution and plot them so we can get and idea what this distribution looks like. Here is a plot of 400 data values from it:
We can see that roughly the standard deviation is about \(\sigma=12\).
You can also see that most of the data is between \(\mu-3(\sigma)\) and \(\mu+3(\sigma)\), which is the same as \(z=-3\) up to \(z=+3\):
Let's see what those values are:
- \(\mu-3\sigma=50-3(12)=14\)
- \(\mu+3\sigma=50+3(12)=86\)
We know this is true for every normal curve actually. Most of the data is within 3 standard deviations of the mean.
22.3 Taking Sample Means
Now we will take samples from this distribution. For each sample we pick 10 data values from the original distribution and and then compute the sample mean \(\bar x\) for that sample.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | x̄ | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample 1 | 69 | 55 | 55 | 53 | 59 | 45 | 66 | 22 | 63 | 52 | 53.9 |
| Sample 2 | 36 | 52 | 20 | 44 | 56 | 47 | 54 | 60 | 48 | 55 | 47.2 |
| Sample 3 | 54 | 57 | 46 | 50 | 61 | 40 | 48 | 47 | 35 | 50 | 48.8 |
| Sample 4 | 29 | 61 | 56 | 53 | 54 | 31 | 38 | 55 | 41 | 56 | 47.4 |
| Sample 5 | 50 | 54 | 47 | 51 | 63 | 62 | 35 | 55 | 64 | 45 | 52.6 |
Suppose we continue and do this 400 times…
Let's take a look at the sample means in a histogram:
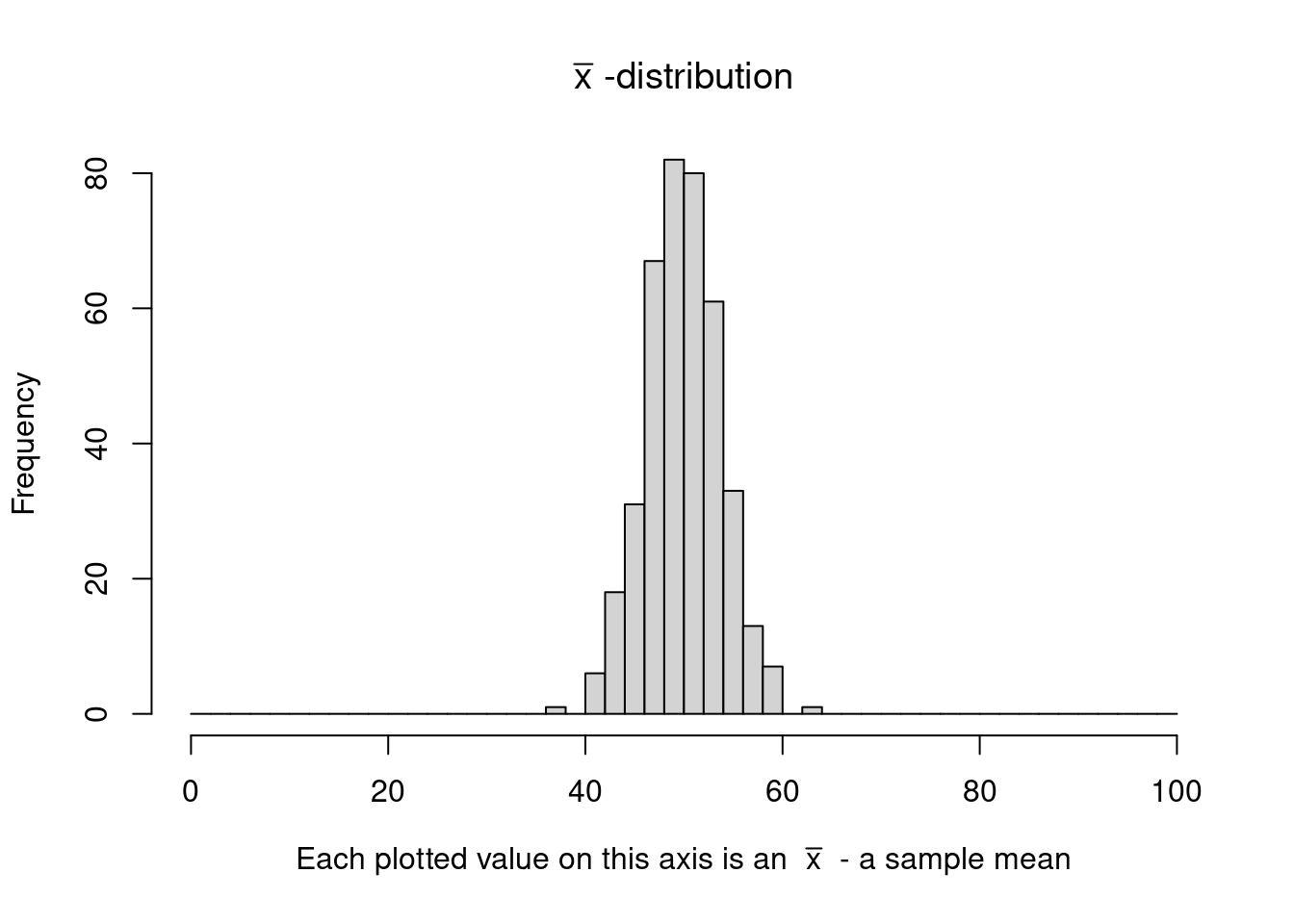
This distribution is called the \(\bar x\)-distribution. or the sampling distribution of sample means.
It is a very important distribution in statistics.
22.4 Sampling Distribution of Sample Means (\(\bar x\)-distribution)
One important thing we can see is that the shape of the \(\bar x\)-distribution is normal.
Next how does it compare to the original \(x\)-distribution?
Let's see the graphs of the original \(x\)-distribution and the \(\bar x\)-distribution side by side:
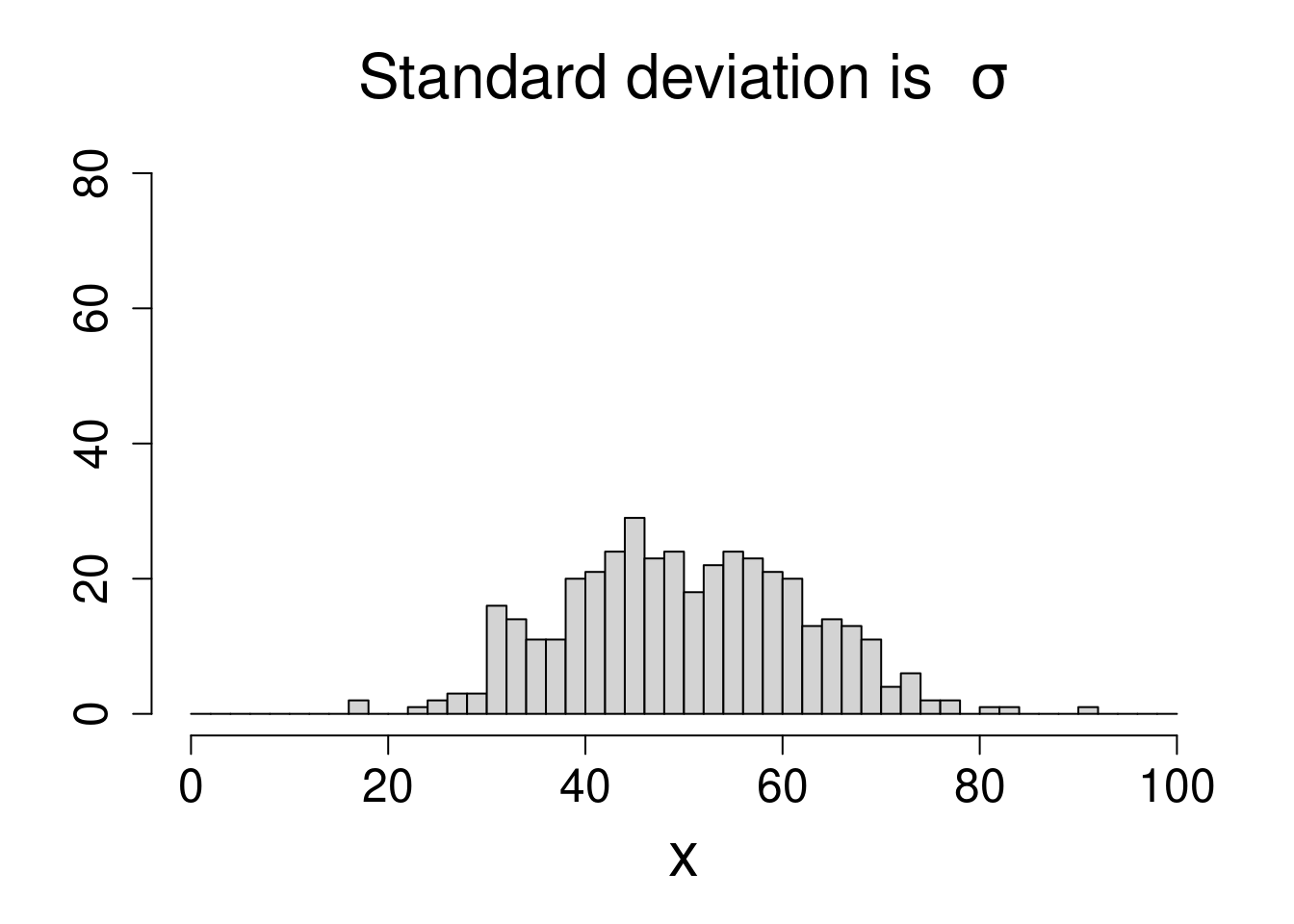

We can clearly see that the \(\bar x\)-distribution is not as spread out as the original \(x\)-distribution. This is because when you take sample means, it averages the data out and when that happens it is more clustered towards the middle.
In fact this clustering towards the middle is one of the main ideas of the Central Limit Theorem below.
And it turns out that we can tell how "squished" the \(\bar x\)-distribution is…
The squish factor is just given by \(\sqrt{n}\):
\[ \text{standard deviation of the }\bar x\text{-distribution} = \frac{\sigma}{\sqrt{n}} \]
where \(\sigma\) is the standard deviation of the original \(x\)-distribution.
So for example if we took an \(\bar x\) using:
- \(n=100\) that would mean the "squish" factor is \(\sqrt{100}=10\), the spread is reduced by factor of \(10\)
- \(n=36\) that would mean the "squish" factor is \(\sqrt{36}=6\), the spread is reduced by factor of \(6\)
So for the example above that we used the squish factor is:
\[ \sqrt{n} = \sqrt{10}=3.1622777 \]
So the standard deviation of the \(\bar x\)-distribution is:
\[ \frac{\sigma}{\sqrt{n}} = \frac{12}{\sqrt{10}} = \frac{12}{3.1622777}= 3.7947332 \]
So the \(\bar x\)-distribution is more concentrated around the center \(\mu\)
And finally its important to note that sampling distributions are made by repeatedly taking samples then computing a statistic, then collecting that data and graphing it in a histogram.
22.5 Central Limit Theorem - Means
It turns out that this "normal curve" shape turns up all the time for sampling distributions under the right conditions, and that fact is called the Central Limit Theorem.
This is one of the most important results in statistics and basically it tells us that we can use a normal distribution to approximate the sampling distribution (the \(\bar x\)-distribution that is).
This will allow us to calculate areas for the \(\bar x\)-distribution by calculating z-values and using a standard normal curve to find areas we want.
Theorem 22.1 (Central Limit Theorem - Means)
Suppose we have a large population with population mean \(\mu\) and standard deviation \(\sigma\) and consider samples of size \(n\) from this population.
If \(n>30\) or if the population we start with is approximately normal:
- The \(\bar x\) distribution is normal
- The mean and standard deviation of the \(\bar x\) distribution are given by these formulas:
\[ \text{mean} = \mu \]
\[ \text{standard deviation} = \frac{\sigma}{\sqrt{n}} \]
Note:
- if the population we start with is approximately normal the result is true for any sample size (even \(n \leq 30\)).
- if the population we start with is not approximately normal, we must have \(n>30\) for the result to be true.
The first bullet point of this theorem means:
- we can use a standard normal table to calculate areas under the \(\bar x\)-distribution
The second bullet point of the theorem means:
- the \(\bar x\)-distribution has \(\mu\) as its center, and the standard deviation we can compute with the formula in the theorem.
22.6 How to Calculate \(\bar x\)-distribution Areas
So to find areas under the \(\bar x\)-distribution we will just convert them to areas under a standard normal curve like we did before but this time we will use this formula for the z-scores:
\[ z=\frac{\bar x-\mu}{\frac{\sigma}{\sqrt{n}}} \]
So just like before we will find left tails, right tails and areas between but this time using the z-value formula above.
22.7 Examples of Areas For \(\bar x\)-distribution
Lets see some examples of computing areas for the \(\bar x\)-distribution.
First lets see how to compute a left tail area:
Example 22.1 (Left tail area for \(\bar x\)-distribution when \(\bar x=210\) \(\mu=220\) \(\sigma=100\), and \(n=10\))
Suppose that a normal distribution has a mean of \(220\) and a standard deviation of \(100\). If we take samples of size \(10\) from this distribution what is the chance that \(\bar x\) will be \(210\) or less?
Solution:
We have \(\bar x=210\), \(\mu =220\), \(\sigma=100\) and \(n=10\).
We are interested in how likely it is to get a sample mean \(\bar x=210\) or below for the \(\bar x\)-distribution here.
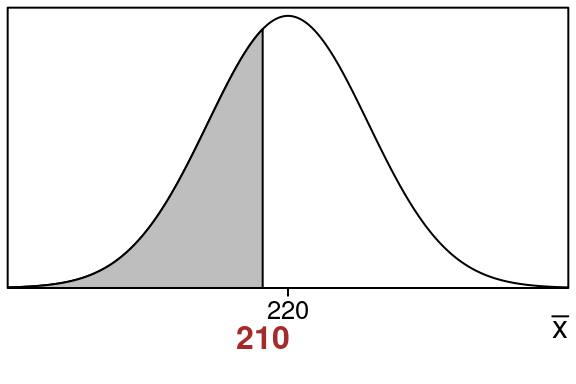
Here is the \(\bar x\)-distribution showing the area that we want:
Notice:
- The sample mean \(\bar x=210\) is at the edge of the shaded region we want to find
- The population mean \(\mu =220\) is in the center
We want the shaded left tail area that is to the left of \(\bar x = 210\):
We will find this area by changing the sample mean \(\bar x\) into a z-value and then using standard normal table.
Lets find the z-value using the form of the z-value formula for the \(\bar x\)-distribution:
\[\begin{equation} z=\frac{\bar x-\mu}{\frac{\sigma}{\sqrt{n}}} =\frac{210-220}{\frac{100}{\sqrt{10}}} =\frac{-10}{31.6227766} =-0.32 \end{equation}\]
Note that we use the \(\sqrt{n}\) in the denominator. This is because we are using the \(\bar x\)-distribution.
So here is the equivalent left tail area for of \(z=-0.32\).
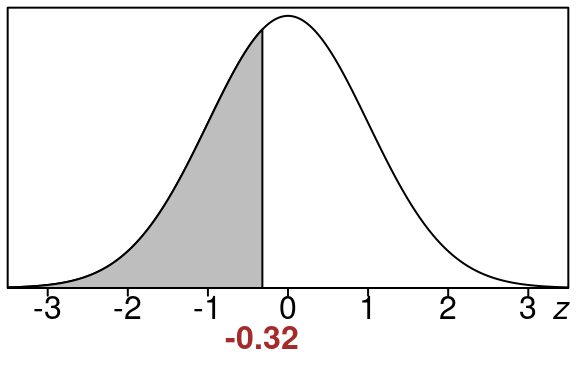
This area is the same size as our original area so we just find this one using the standard normal distribution.
We can look up the area in the standard normal z-table using \(z=-0.32\)
We go to the row that has -0.3 and then to the column that contains .02 and we see this:
| .00 | .01 | .02 | .03 | .04 | .05 | .06 | .07 | .08 | .09 | |
| -0.4 | .3446 | .3409 | .3372 | .3336 | .3300 | .3264 | .3228 | .3192 | .3156 | .3121 |
| -0.3 | .3821 | .3783 | .3745 | .3707 | .3669 | .3632 | .3594 | .3557 | .3520 | .3483 |
| -0.2 | .4207 | .4168 | .4129 | .4090 | .4052 | .4013 | .3974 | .3936 | .3897 | .3859 |
So that means:
\[\begin{equation} \text{left tail area} =0.3745 \end{equation}\]
Rounded to the nearest percent this is 37%. This means that the shaded area corresponds to 37% of the entire data.
This means there is a 37% chance of getting a sample proportion of \(\bar x=210\) or less for the \(\bar x\)-distribution with sample size of \(n=10\).
\[ \tag*{$\blacksquare$} \]
Now lets see how to compute a right tail area:
Example 22.2 (Right tail area for \(\bar x\)-distribution when \(\bar x=80\) \(\mu=90\) \(\sigma=50\), and \(n=20\))
Suppose that a normal distribution has a mean of \(90\) and a standard deviation of \(50\). If we take samples of size \(20\) from this distribution what is the chance that \(\bar x\) will be \(80\) or more?
Solution:
We have \(\bar x=80\), \(\mu =90\), \(\sigma=50\) and \(n=20\).
We are interested in how likely it is to get a sample mean \(\bar x=80\) or above for the \(\bar x\)-distribution.
Here is the \(\bar x\)-distribution showing the area that we want:
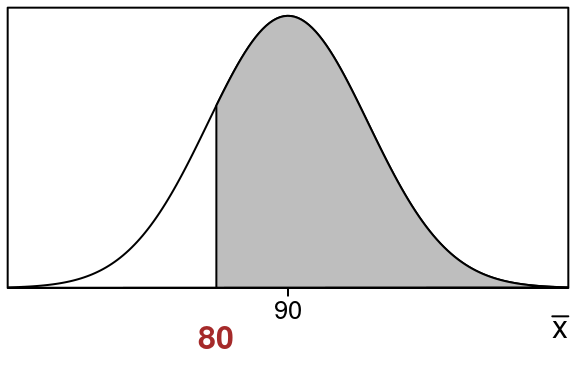
Notice:
- The sample mean \(\bar x=80\) is at the edge of the shaded region we want to find
- The population mean \(\mu =90\) is in the center
We want the shaded right tail area that is to the right of \(\bar x = 80\):
We will find this area by changing the sample mean \(\bar x\) into a z-value and then using standard normal table.
Lets find the z-value using the form of the z-value formula for the \(\bar x\)-distribution:
\[\begin{equation} z=\frac{\bar x-\mu}{\frac{\sigma}{\sqrt{n}}} =\frac{80-90}{\frac{50}{\sqrt{20}}} =\frac{-10}{11.1803399} =-0.89 \end{equation}\]
Note that we use the \(\sqrt{n}\) in the denominator. This is because we are using the \(\bar x\)-distribution.
So here is the equivalent left tail area for of \(z=-0.89\).
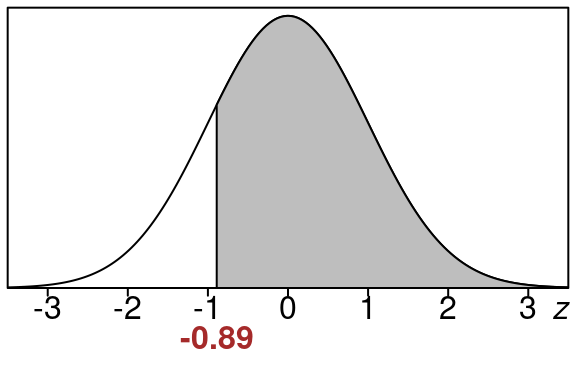
This area is the same size as our original area so we just find this one using the standard normal distribution.
We can find the right tail area for \(z=-0.89\) by finding the left tail area and then subtracting that from 1.0.
So lets look up the left tail area first. Go to the row that has -0.8 and then to the column that contains .09 and we see this:
| .00 | .01 | .02 | .03 | .04 | .05 | .06 | .07 | .08 | .09 | |
| -0.9 | .1841 | .1814 | .1788 | .1762 | .1736 | .1711 | .1685 | .1660 | .1635 | .1611 |
| -0.8 | .2119 | .2090 | .2061 | .2033 | .2005 | .1977 | .1949 | .1922 | .1894 | .1867 |
| -0.7 | .2420 | .2389 | .2358 | .2327 | .2296 | .2266 | .2236 | .2206 | .2177 | .2148 |
So that means:
\[\begin{equation} \text{left tail area} =0.1867 \end{equation}\]
This means that the right tail that we want to find is going to be this left tail subtracted from 1.0.
\[\begin{equation} \text{right tail area} = 1.0 - 0.1867 = 0.8133 \end{equation}\]
Rounded to the nearest percent this is 81%. This means the shaded right tail area corresponds to 81% of the entire data.
This means there is a 81% chance of getting a sample mean of \(\bar x=80\) or more for this population when using samples of size \(n = 20\).
\[ \tag*{$\blacksquare$} \]
22.8 Applications of Sampling Distribution of Sample Means
Example 22.3 (Average Monthly Demand)
Suppose that monthly demand in units for a retail product is given by a normal distribution that has a mean of \(48\) and standard deviation \(14\). Find the chance that that the average demand for the next 12 months is \(40\) or fewer units.
Solution:
We have \(\bar x=40\), \(\mu =48\), \(\sigma=14\) and \(n=12\).
We are interested in how likely it is to get a sample mean \(\bar x=40\) or below for the \(\bar x\)-distribution here.
Here is the \(\bar x\)-distribution showing the area that we want:

Notice:
- The sample mean \(\bar x=40\) is at the edge of the shaded region we want to find
- The population mean \(\mu =48\) is in the center
We want the shaded left tail area that is to the left of \(\bar x = 40\):
We will find this area by changing the sample mean \(\bar x\) into a z-value and then using standard normal table.
Lets find the z-value using the form of the z-value formula for the \(\bar x\)-distribution:
\[\begin{equation} z=\frac{\bar x-\mu}{\frac{\sigma}{\sqrt{n}}} =\frac{40-48}{\frac{14}{\sqrt{12}}} =\frac{-8}{4.0414519} =-1.98 \end{equation}\]
Note that we use the \(\sqrt{n}\) in the denominator. This is because we are using the \(\bar x\)-distribution.
So here is the equivalent left tail area for of \(z=-1.98\).
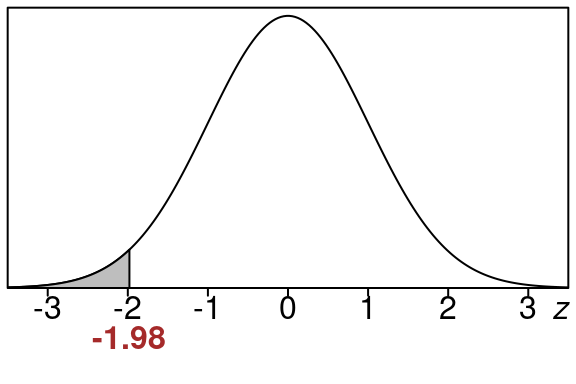
This area is the same size as our original area so we just find this one using the standard normal distribution.
We can look up the area in the standard normal z-table using \(z=-1.98\)
We go to the row that has -1.9 and then to the column that contains .08 and we see this:
| .00 | .01 | .02 | .03 | .04 | .05 | .06 | .07 | .08 | .09 | |
| -2.0 | .0228 | .0222 | .0217 | .0212 | .0207 | .0202 | .0197 | .0192 | .0188 | .0183 |
| -1.9 | .0287 | .0281 | .0274 | .0268 | .0262 | .0256 | .0250 | .0244 | .0239 | .0233 |
| -1.8 | .0359 | .0351 | .0344 | .0336 | .0329 | .0322 | .0314 | .0307 | .0301 | .0294 |
So that means:
\[\begin{equation} \text{left tail area} =0.0239 \end{equation}\]
Rounded to the nearest percent this is 2%. This means that the shaded area corresponds to 2% of the entire data.
This means there is a 2% chance of getting a sample proportion of \(\bar x=40\) or less for the \(\bar x\)-distribution with sample size of \(n=12\). This is the chance the average demand for the next year is \(40\) or less.
\[ \tag*{$\blacksquare$} \]